数据结构与算法
数据结构与算法
数组/Array
数组是存放在连续内存空间上的相同类型数据的集合。
需要两点注意的是
- 数组下标都是从0开始的。
- 数组内存空间的地址是连续的
正是因为数组的在内存空间的地址是连续的,所以我们在删除或者增添元素的时候,就难免要移动其他元素的地址。
数组的元素是不能删的,只能覆盖。
An array is a collection of identical data types stored in contiguous memory locations. There are two important points to note:
- Array indices start from 0.
- Memory addresses of array elements are contiguous.
Because of the contiguous memory addresses of array elements, when we delete or add elements, it’s inevitable that we need to shift the addresses of other elements.
Array elements cannot be deleted; they can only be overwritten.
二分法/Binary Search
时间复杂度:O(logn)
区间的定义就是不变量。要在二分查找的过程中,保持不变量,就是在while寻找中每一次边界的处理都要坚持根据区间的定义来操作,这就是循环不变量规则。
写二分法,区间的定义一般为两种,左闭右闭即[left, right],或者左闭右开即[left, right)。一般不用左开右闭。
通常使用左闭右闭,易于理解
class Solution {
public int search(int[] nums, int target) {
// 避免当 target 小于nums[0] nums[nums.length - 1]时多次循环运算
if (target < nums[0] || target > nums[nums.length - 1]) {
return -1;
}
int left = 0, right = nums.length - 1;
while (left <= right) { // 试想[1, 1]这样的区间,如果不等于无法取值
int mid = left + ((right - left) >> 1); // 取区域中点
if (nums[mid] == target)
return mid;
else if (nums[mid] < target)
left = mid + 1; // mid已被排除在外,不能包含在内
else if (nums[mid] > target)
right = mid - 1; // 同上
}
return -1;
}
}
双指针/Two Pointers
双指针时间复杂度:O(n)
双指针技巧主要分为两类:左右指针和快慢指针。
左右指针,就是两个指针相向而行或者相背而行;
快慢指针,就是两个指针同向而行,一快一慢。
滑动窗口/Sliding Window
滑动窗口时间复杂度:O(n)
滑动窗口的精妙之处在于根据当前子序列和大小的情况,不断调节子序列的起始位置。从而将O(n^2)的暴力解法降为O(n)。
class Solution {
// 滑动窗口
public int minSubArrayLen(int s, int[] nums) {
int left = 0; // 滑动窗口起始位置
int sum = 0; // 滑动窗口数值之和
int result = Integer.MAX_VALUE;
for (int right = 0; right < nums.length; right++) {
sum += nums[right];
// 调整起始位置直到s < sum
while (sum >= s) {
result = Math.min(result, right - left + 1);
sum -= nums[left++];
}
}
return result == Integer.MAX_VALUE ? 0 : result;
}
}
前缀和数组/Prefix Sum Array
前缀和技巧适用于快速、频繁地计算一个索引区间内的元素之和。
class NumArray {
private int[] preSum;
public NumArray(int[] nums) {
preSum = new int[nums.length + 1];
// 计算 nums 的累加和
for (int i = 1; i < preSum.length; i++) {
preSum[i] = preSum[i - 1] + nums[i - 1];
}
}
public int sumRange(int left, int right) {
return preSum[right + 1] - preSum[left];
}
}
差分数组/Difference Array
差分数组的主要适用场景是频繁对原始数组的某个区间的元素进行增减。
比如说,我给你输入一个数组 nums,然后又要求给区间 nums[2..6] 全部加 1,再给 nums[3..9] 全部减 3,再给 nums[0..4] 全部加 2,再给…
一通操作猛如虎,然后问你,最后 nums 数组的值是什么?
常规的思路很容易,你让我给区间 nums[i..j] 加上 val,那我就一个 for 循环给它们都加上呗,还能咋样?这种思路的时间复杂度是 O(N),由于这个场景下对 nums 的修改非常频繁,所以效率会很低下。
这里就需要差分数组的技巧,类似前缀和技巧构造的 preSum 数组,我们先对 nums 数组构造一个 diff 差分数组,diff[i] 就是 nums[i] 和 nums[i-1] 之差:
int[] res = new int[diff.length];
// 根据差分数组构造结果数组
res[0] = diff[0];
for (int i = 1; i < diff.length; i++) {
res[i] = res[i - 1] + diff[i];
}
这样构造差分数组 diff,就可以快速进行区间增减的操作,如果你想对区间 nums[i..j] 的元素全部加 3,那么只需要让 diff[i] += 3,然后再让 diff[j+1] -= 3 即可
链表/Linked list
链表的种类主要为:单链表,双链表,循环链表
链表的存储方式:链表的节点在内存中是分散存储的,通过指针连在一起。
链表是如何进行增删改查的。
数组和链表在不同场景下的性能分析。
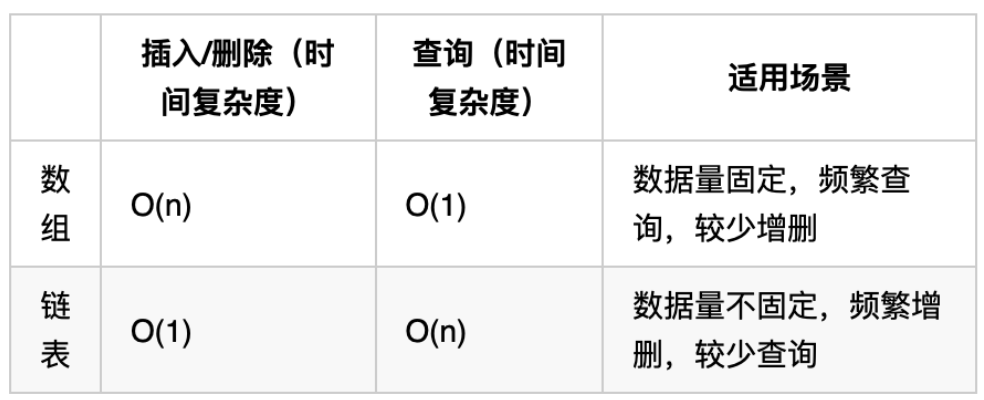
数组在定义的时候,长度就是固定的,如果想改动数组的长度,就需要重新定义一个新的数组。
链表的长度可以是不固定的,并且可以动态增删, 适合数据量不固定,频繁增删,较少查询的场景。
虚拟头节点/Dummy Head Node
有时可以设置一个虚拟头结点,这样原链表的所有节点就都可以按照统一的方式进行移除了。一般建议采用虚拟头节点,会让操作方便很多。
双指针/Two Pointers
双指针技巧主要分为两类:左右指针和快慢指针。
左右指针,就是两个指针相向而行或者相背而行;
快慢指针,就是两个指针同向而行,一快一慢。
递归/Recursion
值得一提的是,递归操作链表并不高效。和迭代解法相比,虽然时间复杂度都是 O(N),但是迭代解法的空间复杂度是 O(1),而递归解法需要堆栈,空间复杂度是 O(N)。所以递归操作链表可以作为对递归算法的练习或者拿去和小伙伴装逼,但是考虑效率的话还是使用迭代算法更好。
哈希表/Hash Table
一般来说哈希表都是用来快速判断一个元素是否出现集合里。
对于哈希表,要知道哈希函数和哈希碰撞在哈希表中的作用.
哈希函数是把传入的key映射到符号表的索引上。
哈希碰撞处理有多个key映射到相同索引上时的情景,处理碰撞的普遍方式是拉链法和线性探测法。
接下来是常见的三种哈希结构:
- 数组
- set(集合)
- map(映射)
集合/Collection
| 数据结构 | 底层实现 | 是否有序 | 数值是否可以重复 | 能否更改数值 | 查询效率 | 增删效率 |
|---|---|---|---|---|---|---|
| HashSet | 哈希表 | 无序 | 不可重复 | 是 | 平均情况下 O(1) | 平均情况下 O(1) |
| TreeSet | 红黑树 | 有序 | 不可重复 | 是 | 平均情况下 O(log n) | 平均情况下 O(log n) |
映射/Map
| 数据结构 | 底层实现 | 是否有序 | key是否可重复 | 能否更改key | 查询效率 | 增删效率 |
|---|---|---|---|---|---|---|
| HashMap | 哈希表 | 无序 | 不可重复 | 是 | 平均情况下 O(1) | 平均情况下 O(1) |
| TreeMap | 红黑树 | 有序 | 不可重复 | 是 | 平均情况下 O(log n) | 平均情况下 O(log n) |
字符串/String
字符串是若干字符组成的有限序列,也可以理解为是一个字符数组。
双指针/Two Pointers
同上
KMP算法/KMP Algorithm
目的:解决字符串匹配问题
KMP的主要思想是当出现字符串不匹配时,可以知道一部分之前已经匹配的文本内容,可以利用这些信息避免从头再去做匹配了。
因为是由这三位学者发明的:Knuth,Morris和Pratt,所以取了三位学者名字的首字母KMP。
前缀表/Prefix Table
写过KMP的同学,一定都写过next数组,那么这个next数组究竟是个啥呢?
next数组就是一个前缀表(prefix table)。
前缀表有什么作用呢?
前缀表是用来回退的,它记录了模式串与主串(文本串)不匹配的时候,模式串下一步(next)应该从哪里开始重新匹配。
前缀表是如何记录的呢?
首先要知道前缀表的任务是当前位置匹配失败,找到之前已经匹配上的位置,再重新匹配,此也意味着在某个字符失配时,前缀表会告诉你下一步匹配中,模式串应该跳到哪个位置。
那么什么是前缀表:记录下标i之前(包括i)的字符串中,有多大长度的相同前缀后缀,即最长相等前后缀/最长公共子串。
前缀是指不包含最后一个字符的所有以第一个字符开头的连续子串。
后缀是指不包含第一个字符的所有以最后一个字符结尾的连续子串。
private void getNext(int[] next, String s) {
int j = 0;
next[0] = 0;
for (int i = 1; i < s.length(); i++) {
// j为前缀最后的下标,接下来事实上是为了保证前缀子串和后缀子串的最后一个字母能相同
while (j > 0 && s.charAt(j) != s.charAt(i))
j = next[j - 1];
if (s.charAt(j) == s.charAt(i))
j++;
next[i] = j;
}
}
最难的部分在于
while (j > 0 && s.charAt(j) != s.charAt(i)) j = next[j - 1];
这一段事实上相当于在利用前缀表求前缀表,因为我们只需要对比前缀子串和后缀子串的最后一个字母能相同,即可求得next数组的值,那么除了最后一个字母外,剩下的部分早已经在前缀表中求过了。
栈与队列/Stack and Queue
队列是先进先出,栈是先进后出。
二叉树/Binary Tree
二叉树主要有两种遍历方式:
- 深度优先遍历:先往深走,遇到叶子节点再往回走。
- 广度优先遍历:一层一层的去遍历。
这两种遍历是图论中最基本的两种遍历方式,后面在介绍图论的时候 还会介绍到。
那么从深度优先遍历和广度优先遍历进一步拓展,才有如下遍历方式:
- 深度优先遍历
- 前序遍历(递归法,迭代法)
- 中序遍历(递归法,迭代法)
- 后序遍历(递归法,迭代法)
- 广度优先遍历
- 层次遍历(迭代法)
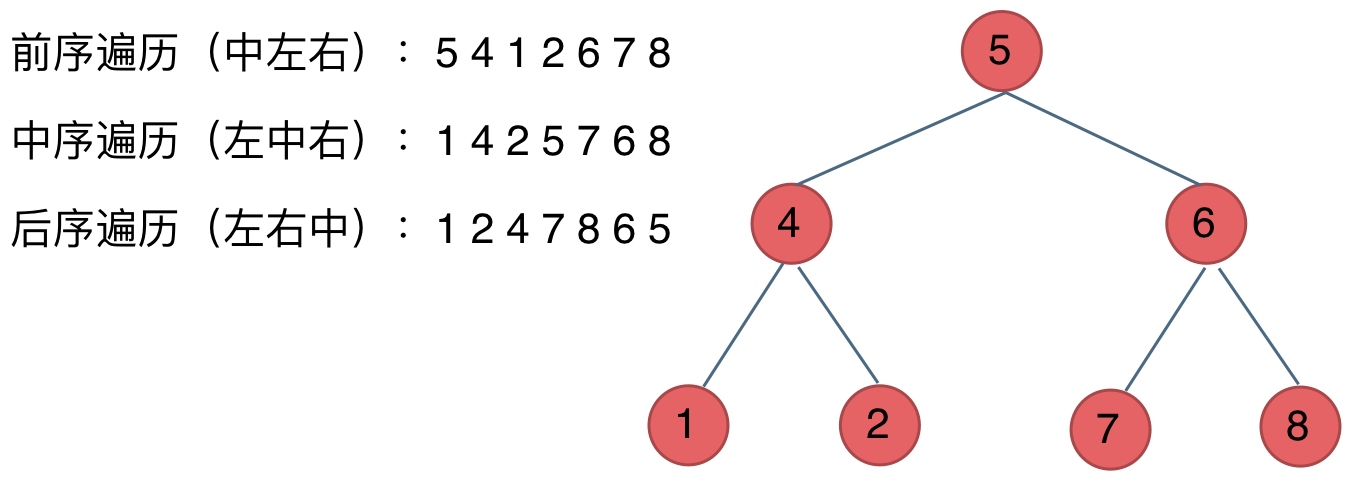
在深度优先遍历中:有三个顺序,前中后序遍历, 有同学总分不清这三个顺序,经常搞混,我这里教大家一个技巧。
这里前中后,其实指的就是中间节点的遍历顺序,只要大家记住 前中后序指的就是中间节点的位置就可以了。
看如下中间节点的顺序,就可以发现,中间节点的顺序就是所谓的遍历方式
- 前序遍历:中左右
- 中序遍历:左中右
- 后序遍历:左右中
大家可以对着如下图,看看自己理解的前后中序有没有问题。
最后再说一说二叉树中深度优先和广度优先遍历实现方式,我们做二叉树相关题目,经常会使用递归的方式来实现深度优先遍历,也就是实现前中后序遍历,使用递归是比较方便的。
之前我们讲栈与队列的时候,就说过栈其实就是递归的一种实现结构,也就说前中后序遍历的逻辑其实都是可以借助栈使用递归的方式来实现的。
而广度优先遍历的实现一般使用队列来实现,这也是队列先进先出的特点所决定的,因为需要先进先出的结构,才能一层一层的来遍历二叉树。
- 递归函数可以理解为一个指针
- 前中后序是三个特殊的时间点
- 二叉树遍历算法需要思考的两个问题
- 当前的节点需要做什么事情?
- 应该在什么时候去做,是在前序还是中序还是后序?
- 二叉树算法的两大分类
- 回溯算法
- 动态规划
归并排序/Merge Sort
快速排序、快速选择/Quick Sort and Quick Select
经典top k问题,[215. 数组中的第K个最大元素]
二叉搜索树/Binary Search Tree(BST)
普通二叉树思路
- 是否可以遍历一遍出结果?
- 是否可以把原问题分解为子问题?
优化算法的核心
- 充分利用信息
- 消除冗余计算
对于数据结构的操作
遍历
访问
BST可以高效遍历
左分支所有的node的val必然小于root,右分支所有的node的val必然大于root
回溯算法/backtracking
回溯法的性能如何呢,这里要和大家说清楚了,虽然回溯法很难,很不好理解,但是回溯法并不是什么高效的算法。
因为回溯的本质是穷举,穷举所有可能,然后选出我们想要的答案,如果想让回溯法高效一些,可以加一些剪枝的操作,但也改不了回溯法就是穷举的本质。
那么既然回溯法并不高效为什么还要用它呢?
因为没得选,一些问题能暴力搜出来就不错了,撑死了再剪枝一下,还没有更高效的解法。
回溯法解决的问题
回溯法,一般可以解决如下几种问题:
- 组合问题:N个数里面按一定规则找出k个数的集合
- 切割问题:一个字符串按一定规则有几种切割方式
- 子集问题:一个N个数的集合里有多少符合条件的子集
- 排列问题:N个数按一定规则全排列,有几种排列方式
- 棋盘问题:N皇后,解数独等等
如何理解回溯法
回溯法解决的问题都可以抽象为树形结构,是的,我指的是所有回溯法的问题都可以抽象为树形结构!
因为回溯法解决的都是在集合中递归查找子集,集合的大小就构成了树的宽度,递归的深度,都构成的树的深度。
递归就要有终止条件,所以必然是一棵高度有限的树(N叉树)。
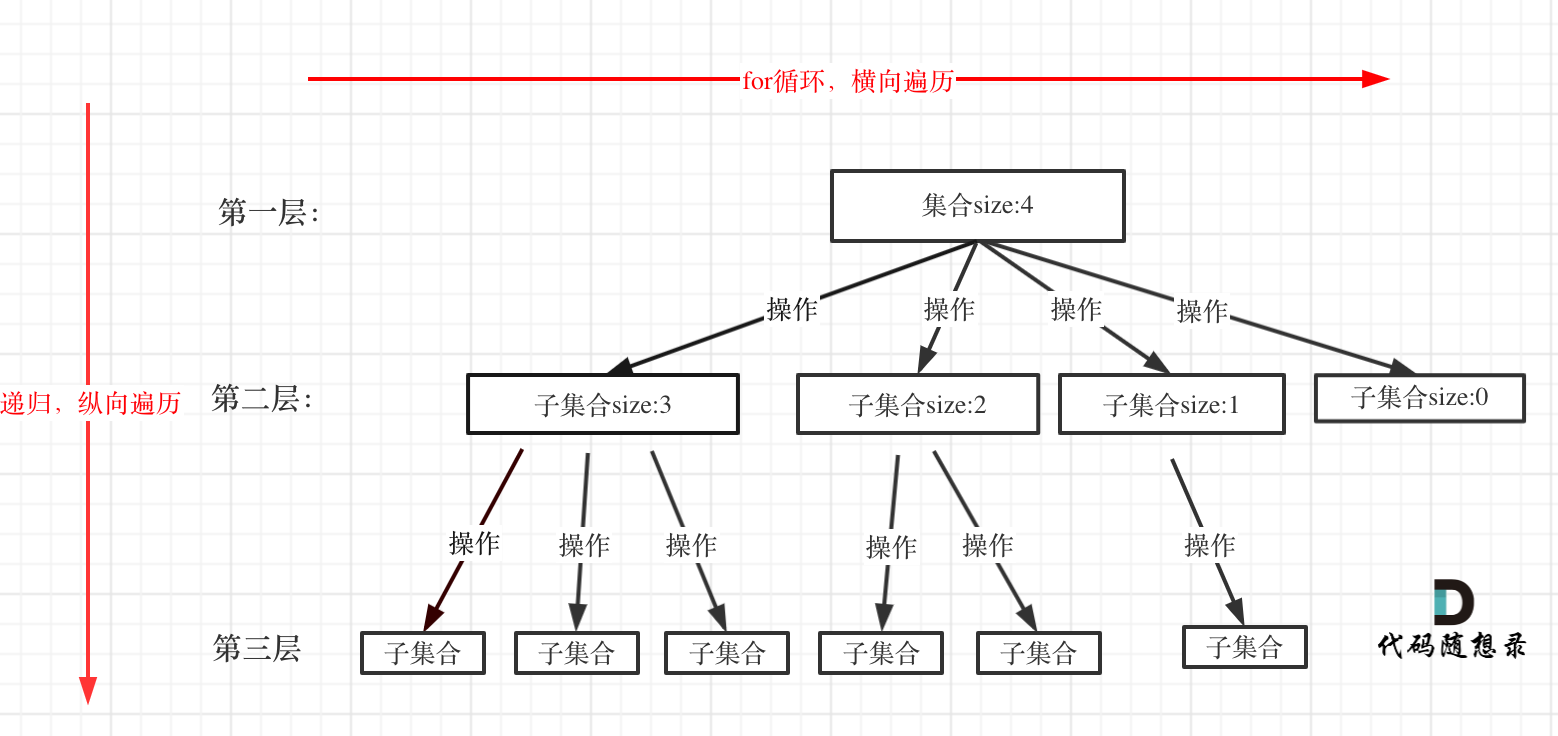
回溯算法模板框架:
回溯法一般是在集合中递归搜索,集合的大小构成了树的宽度,递归的深度构成的树的深度。
如图:
void backtracking(参数) {
if (终止条件) {
存放结果;
return;
}
for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) {
处理节点;
backtracking(路径,选择列表); // 递归
回溯,撤销处理结果
}
}
本质就是dfs
图/Graph
dfs 与 bfs 区别
- dfs是可一个方向去搜,不到黄河不回头,直到遇到绝境了,搜不下去了,再换方向(换方向的过程就涉及到了回溯)。
- bfs是先把本节点所连接的所有节点遍历一遍,走到下一个节点的时候,再把连接节点的所有节点遍历一遍,搜索方向更像是广度,四面八方的搜索过程。
- 二叉树的递归法其实就是dfs,而二叉树的迭代法,就是bfs(广度优先搜索)
深度优先算法/Deep First Search(DFS)
回溯法 (opens new window)的代码框架,属于dfs的一类特殊情况:
void backtracking(参数) {
if (终止条件) {
存放结果;
return;
}
for (选择:本层集合中元素(树中节点孩子的数量就是集合的大小)) {
处理节点;
backtracking(路径,选择列表); // 递归
回溯,撤销处理结果
}
}
dfs的代码框架:
void dfs(参数) {
if (终止条件) {
存放结果;
return;
}
for (选择:本节点所连接的其他节点) {
处理节点;
dfs(图,选择的节点); // 递归
回溯,撤销处理结果
}
}
广度优先算法/ Breath First Search(BFS)
// 计算从起点 start 到终点 target 的最近距离
int BFS(Node start, Node target) {
Queue<Node> q; // 核心数据结构
Set<Node> visited; // 避免走回头路
q.offer(start); // 将起点加入队列
visited.add(start);
while (q not empty) {
int sz = q.size();
/* 将当前队列中的所有节点向四周扩散 */
for (int i = 0; i < sz; i++) {
Node cur = q.poll();
/* 划重点:这里判断是否到达终点 */
if (cur is target)
return step;
/* 将 cur 的相邻节点加入队列 */
for (Node x : cur.adj()) {
if (x not in visited) {
q.offer(x);
visited.add(x);
}
}
}
}
// 如果走到这里,说明在图中没有找到目标节点
}
动态规划/Dynamic Programming
01背包问题/0-1 Knapsack Problem
使用一位数组时为何要用倒序遍历的原因
首先要明白二维数组的递推过程,然后才能看懂二维变一维的过程。
假设目前有背包容量为10,可以装的最大价值, 记为g(10)。
即将进来的物品重量为6。价值为9。 那么此时可以选择装该物品或者不装该物品。
如果不装该物品,显然背包容量无变化,这里对应二维数组,其实就是取该格子上方的格子复制下来,就是所说的滚动下来,直接g[10] = g[10],这两个g[10]要搞清楚,右边的g[10]是上一轮记录的,也就是对应二维数组里上一层的值,而左边是新的g[10],也就是对应二维数组里下一层的值。
如果装该物品,则背包容量 g(10) = g(4) + 6 ,这里的6是新进来的物品的价值,g(10)就是新记录的,对应二维数组里下一层的值,而这里的g(4)是对应二维数组里上一层的值,通俗的来讲:你要找到上一层也就是上一状态下 背包容量为4时的能装的最大价值,用它来更新下一层的这一状态,也就是加入了价值为9的物品的新状态。
这时候如果是正序遍历会怎么样? g(10) = g(4) + 6 ,这个式子里的g(4)就不再是上一层的了,因为你是正序啊,g(4) 比g(10)提前更新,那么此时程序已经没法读取到上一层的g(4)了,新更新的下一层的g(4)覆盖掉了,这里也就是为啥有题解说一件物品被拿了两次的原因。
- 01背包问题的本质是需要取上一行的数据(dp[j - weight[i]] + value[i])比较,完全背包的问题本质是要取同一行左边的数据比较
- 01背包在容量上要倒序遍历,完全背包要正序遍历
搜索
| 算法 | 数据结构 | 时间复杂度 | 空间复杂度 | |
|---|---|---|---|---|
| 平均 | 最差 | 最差 | ||
| 深度优先搜索 (DFS) | Graph of |V| vertices and |E| edges | - | `O( | E |
| 广度优先搜索 (BFS) | Graph of |V| vertices and |E| edges | - | `O( | E |
| 二分查找 | Sorted array of n elements | O(log(n)) | O(log(n)) | O(1) |
| 穷举查找 | Array | O(n) | O(n) | O(1) |
| 最短路径-Dijkstra,用小根堆作为优先队列 | Graph with |V| vertices and |E| edges | `O(( | V | + |
| 最短路径-Dijkstra,用无序数组作为优先队列 | Graph with |V| vertices and |E| edges | `O( | V | ^2)` |
| 最短路径-Bellman-Ford | Graph with |V| vertices and |E| edges | `O( | V |
排序
| 算法 | 数据结构 | 时间复杂度 | 最坏情况下的辅助空间复杂度 | ||
|---|---|---|---|---|---|
| 最佳 | 平均 | 最差 | 最差 | ||
| 快速排序 | 数组 | O(n log(n)) | O(n log(n)) | O(n^2) | O(n) |
| 归并排序 | 数组 | O(n log(n)) | O(n log(n)) | O(n log(n)) | O(n) |
| 堆排序 | 数组 | O(n log(n)) | O(n log(n)) | O(n log(n)) | O(1) |
| 冒泡排序 | 数组 | O(n) | O(n^2) | O(n^2) | O(1) |
| 插入排序 | 数组 | O(n) | O(n^2) | O(n^2) | O(1) |
| 选择排序 | 数组 | O(n^2) | O(n^2) | O(n^2) | O(1) |
| 桶排序 | 数组 | O(n+k) | O(n+k) | O(n^2) | O(nk) |
| 基数排序 | 数组 | O(nk) | O(nk) | O(nk) | O(n+k) |
数据结构
| 数据结构 | 时间复杂度 | 空间复杂度 | |||||||
|---|---|---|---|---|---|---|---|---|---|
| 平均 | 最差 | 最差 | |||||||
| 索引 | 查找 | 插入 | 删除 | 索引 | 查找 | 插入 | 删除 | ||
| 基本数组 | O(1) | O(n) | - | - | O(1) | O(n) | - | - | O(n) |
| 动态数组 | O(1) | O(n) | O(n) | O(n) | O(1) | O(n) | O(n) | O(n) | O(n) |
| 单链表 | O(n) | O(n) | O(1) | O(1) | O(n) | O(n) | O(1) | O(1) | O(n) |
| 双链表 | O(n) | O(n) | O(1) | O(1) | O(n) | O(n) | O(1) | O(1) | O(n) |
| 跳表 | O(log(n)) | O(log(n)) | O(log(n)) | O(log(n)) | O(n) | O(n) | O(n) | O(n) | O(n log(n)) |
| 哈希表 | - | O(1) | O(1) | O(1) | - | O(n) | O(n) | O(n) | O(n) |
| 二叉搜索树 | O(log(n)) | O(log(n)) | O(log(n)) | O(log(n)) | O(n) | O(n) | O(n) | O(n) | O(n) |
| 笛卡尔树 | - | O(log(n)) | O(log(n)) | O(log(n)) | - | O(n) | O(n) | O(n) | O(n) |
| B-树 | O(log(n)) | O(log(n)) | O(log(n)) | O(log(n)) | O(log(n)) | O(log(n)) | O(log(n)) | O(log(n)) | O(n) |
| 红黑树 | O(log(n)) | O(log(n)) | O(log(n)) | O(log(n)) | O(log(n)) | O(log(n)) | O(log(n)) | O(log(n)) | O(n) |
| 伸展树 | - | O(log(n)) | O(log(n)) | O(log(n)) | - | O(log(n)) | O(log(n)) | O(log(n)) | O(n) |
| AVL 树 | O(log(n)) | O(log(n)) | O(log(n)) | O(log(n)) | O(log(n)) | O(log(n)) | O(log(n)) | O(log(n)) | O(n) |
堆
| Heaps | 时间复杂度 | ||||||
|---|---|---|---|---|---|---|---|
| 建堆 | 查找最大值 | 提取最大值 | Increase Key | 插入 | 删除 | 合并 | |
| 链表(已排序) | - | O(1) | O(1) | O(n) | O(n) | O(1) | O(m+n) |
| 链表(未排序) | - | O(n) | O(n) | O(1) | O(1) | O(1) | O(1) |
| 二叉堆 | O(n) | O(1) | O(log(n)) | O(log(n)) | O(log(n)) | O(log(n)) | O(m+n) |
| 二项堆 | - | O(log(n)) | O(log(n)) | O(log(n)) | O(log(n)) | O(log(n)) | O(log(n)) |
| 斐波那契堆 | - | O(1) | O(log(n))* | O(1)* | O(1) | O(log(n))* | O(1) |
图
| 节点 / 边 管理 | Storage | Add Vertex | Add Edge | Remove Vertex | Remove Edge | Query |
|---|---|---|---|---|---|---|
| 邻接表 | `O( | V | + | E | )` | O(1) |
| 关联表 | `O( | V | + | E | )` | O(1) |
| 邻接矩阵 | `O( | V | ^2)` | `O( | V | ^2)` |
| 关联矩阵 | `O( | V | ⋅ | E | )` | `O( |
java语法笔记
除法取整
在Java中,除法运算可以使用/运算符。下面是一个使用Java进行除法运算的示例:
int 被除数 = 10;
int 除数 = 3;
int 结果 = 被除数 / 除数;
System.out.println("结果:" + 结果);
在这个示例中,被除数通过/运算符除以除数,结果存储在结果变量中。输出将是:
结果:3
请注意,如果你对两个整数进行除法运算,结果将会是一个整数,而且任何小数部分都会被舍去。如果你想得到一个带有小数部分的浮点数结果,你可以使用double或float数据类型。例如:
double 被除数 = 10.0;
double 除数 = 3.0;
double 结果 = 被除数 / 除数;
System.out.println("结果:" + 结果);
这将输出:
结果:3.3333333333333335
在这种情况下,结果是一个带有小数部分的double值。
找区域中点
(right - left) >> 1 是 Java 中的位运算写法,用于将两个整数的差值右移一位(相当于除以2),并返回结果。这个操作实际上是在进行整数除法并向下取整。右移一位相当于将二进制表示的数值向右移动一位,导致数值减小一倍。
在这个表达式中,(right - left) 计算了右边界 right 和左边界 left 之间的差值,然后将这个差值右移一位,以得到其整数除以2的结果。
left + ((right - left) >> 1)
可以用于快速计算中间值或区间的中点,但是需要注意:位运算部分必须用括号括起来
这样写相比
(left + right) / 2
可以防止越界。
整数最大值
Integer.MAX_VALUE;
自增自减问题
在Java中,k-- 和 --k 都是自减运算符,但它们在执行时有一些区别。
k--:这是后缀自减运算符。它表示先使用变量的当前值,然后再将变量减 1。换句话说,它会先返回变量的值,然后再执行减 1 操作。int k = 5; int result = k--; // 先将 5 赋值给 result,然后将 k 减 1 // 此时 result = 5, k = 4--k:这是前缀自减运算符。它表示先将变量减 1,然后再使用变量的新值。换句话说,它会先执行减 1 操作,然后返回变量的新值。int k = 5; int result = --k; // 先将 k 减 1,然后将新的值 4 赋值给 result // 此时 result = 4, k = 4
总结:
k--是先使用当前值再减 1。--k是先减 1 再使用新值。
在实际编程中,根据需要选择合适的自减方式是很重要的。
强制转换类型
强制类型转换的语法是在要转换的目标类型前加上括号,将要转换的表达式放在括号内。例如:
double doubleValue = 3.14159;
int intValue = (int) doubleValue; // 强制将 double 转换为 int
以下是一些关于强制类型转换的注意事项:
- 从大范围到小范围的转换: 当你将一个具有大范围值的数据类型转换为一个小范围的数据类型时,可能会导致数据丢失。例如,将 double 转换为 int 可能会丢失小数部分。
- 从小范围到大范围的转换: 通常可以在不进行显式转换的情况下将小范围数据类型转换为大范围数据类型,因为这种转换不会导致数据丢失。
- 对象类型转换: 对于类和接口,需要进行显式的类型转换,但只能在继承关系和接口实现的情况下进行。这涉及到对象的运行时类型。
- 数字类型之间的转换: Java 中数字类型之间的转换遵循一定的规则,如自动提升和强制类型转换。
二维数组
二维数组中,坐标用于准确定位数组中的元素。第一个维度表示行号,第二个维度表示列号。
例如,考虑以下二维数组:
int[][] array = {
{1, 2, 3},
{4, 5, 6},
{7, 8, 9}
};
在这个例子中,数组的坐标代表如下:
array[0][0]代表第一行第一列的元素,即值为 1 的元素。array[1][2]代表第二行第三列的元素,即值为 6 的元素。array[2][1]代表第三行第二列的元素,即值为 8 的元素。
返回空数组
java数组所引用的值在堆中,C是除了malloc的在堆中,而正常使用是在栈中的。
java数组是引用对象,引用对象都需要开辟内存空间,这一点与C相同。
new这个关键字在java中是实例化对象,也为对象开辟了内存空间。
因为java中的对象是在堆中的,所以如果不new一下,是得不到这块空间的。
return new int[0];
对象传递
在Java中,对象是通过引用进行传递的,而不是通过直接复制整个对象。这意味着当你将一个对象分配给一个变量,实际上是将这个变量设置为引用该对象的内存地址。
让我们通过一个简单的示例来解释一下对象传递的概念:
class Person {
String name;
Person(String name) {
this.name = name;
}
}
public class Main {
public static void main(String[] args) {
Person person1 = new Person("Alice");
Person person2 = person1; // 对象传递
person2.name = "Bob"; // 修改 person2 的属性
System.out.println(person1.name); // 输出 "Bob"
}
}
在这个示例中,首先创建了一个名为 person1 的 Person 对象,并将其名字设置为 “Alice”。然后,我们将 person1 赋值给 person2,这实际上是将 person2 设置为引用 person1 对象的内存地址。因此,person1 和 person2 引用了同一个对象。
当我们通过 person2 修改对象的属性时,例如将名字改为 “Bob”,这个修改同时也影响到了 person1,因为它们引用同一个对象。因此,当我们打印 person1.name 时,输出结果是 “Bob”。
关键点:
- 对象传递涉及复制引用,而不是整个对象。因此,任何引用所做的更改都会影响到所有引用同一个对象的变量。
- 基本数据类型(如
int、double等)是按值传递的,这意味着将基本数据类型赋值给另一个变量时,实际上是复制其值,而不是创建引用。因此,在不同变量上的操作不会相互影响。 - 在方法参数传递中,也是通过引用传递。当你将对象作为参数传递给方法时,方法中对对象属性的修改会影响到原始对象。
比较Integer
在Java中,可以使用不同的方法来比较整数(Integer)对象。Integer是一个包装类,用于封装原始的int数据类型。以下是几种比较Integer对象的方法:
使用equals方法:
Integer类继承了Object类的equals方法,因此你可以使用它来比较两个Integer对象的值是否相等。Integer num1 = 5; Integer num2 = 5; if (num1.equals(num2)) { System.out.println("num1 and num2 are equal"); }使用compareTo方法:
Integer类还实现了Comparable接口,因此你可以使用compareTo方法来比较两个Integer对象的大小关系。Integer num1 = 5; Integer num2 = 10; int comparison = num1.compareTo(num2); if (comparison < 0) { System.out.println("num1 is less than num2"); } else if (comparison > 0) { System.out.println("num1 is greater than num2"); } else { System.out.println("num1 and num2 are equal"); }使用基本数据类型比较:你也可以将
Integer对象拆箱为int类型,然后使用常规的比较运算符来比较它们的值。Integer num1 = 5; Integer num2 = 10; if (num1.intValue() < num2.intValue()) { System.out.println("num1 is less than num2"); } else if (num1.intValue() > num2.intValue()) { System.out.println("num1 is greater than num2"); } else { System.out.println("num1 and num2 are equal"); }
无论使用哪种方法,都可以根据需要比较Integer对象的值或大小关系。请注意,如果你只是比较基本数据类型(如int),直接使用比较运算符(如<、>、==)就足够了,不需要使用包装类和比较方法。
return的值
在 Java 中,如果一个方法的返回类型不是void,那么在使用return语句时必须提供相应的返回值。不然,请返回null值。
位运算
Java中的位运算是指对整数的二进制位进行操作的运算。Java提供了几种位运算操作符,用于进行位级别的操作。以下是常见的位运算操作符及其功能:
与运算(&):将两个操作数的对应位进行与操作,只有在两个操作数对应位都为1时,结果位才为1,否则为0。
int result = a & b;
或运算(|):将两个操作数的对应位进行或操作,只要两个操作数对应位有一个为1,结果位就为1,否则为0。
int result = a | b;
异或运算(^):将两个操作数的对应位进行异或操作,相同为0,不同为1。
int result = a ^ b;
非运算(~):对操作数的每个位取反,即0变为1,1变为0。
int result = ~a;
左移运算(«):将操作数的二进制位向左移动指定的位数,右侧补0。
int result = a << n;
右移运算(»):将操作数的二进制位向右移动指定的位数,左侧根据最高位的值进行补位,正数补0,负数补1。
int result = a >> n;
无符号右移运算(»>):将操作数的二进制位向右移动指定的位数,左侧补0。
int result = a >>> n;
这些位运算操作符通常用于处理位掩码、位标志和底层的二进制数据操作。要注意,位运算操作符只能用于整数类型(byte、short、int、long、char),不能用于浮点数。
以下是一个示例,展示如何使用位运算操作符:
int a = 5; // 二进制表示为 0101
int b = 3; // 二进制表示为 0011
int andResult = a & b; // 0001 (1)
int orResult = a | b; // 0111 (7)
int xorResult = a ^ b; // 0110 (6)
int notResult = ~a; // 1010 (-6) - 注意:整数的位表示是补码
int leftShiftResult = a << 2; // 10100 (20)
int rightShiftResult = a >> 1; // 0010 (2)
int unsignedRightShiftResult = a >>> 1; // 0010 (2)
位运算交换变量的值
假设有两个变量 s[i] 和 s[j],初始值分别为 a 和 b。
s[i] ^= s[j];在这一步中,s[i]的值变成了a ^ b。s[j] ^= s[i];在这一步中,s[j]的值变成了b ^ (a ^ b),根据异或的交换律和结合律,可以简化为b ^ a ^ b,也就是a。s[i] ^= s[j];在这一步中,s[i]的值变成了(a ^ b) ^ a,同样可以根据异或的交换律和结合律,简化为a ^ a ^ b,也就是b。
这样,经过这三步操作后,s[i] 的值变成了 b,s[j] 的值变成了 a,实现了交换。
这种方法的优点在于不需要引入额外的临时变量,同时由于位运算是底层的操作,效率较高。然而,需要注意的是,这种交换方法在实际应用中可能会因为代码的可读性较差而不被推荐使用,可以根据具体情况权衡使用。
‘‘和"“的区别
在Java中,''(单引号)和""(双引号)具有不同的含义和用法:
- 单引号 (
''):- 单引号用于表示字符字面量(Character Literal)。
- 在单引号内只能包含一个字符。例如:
'a'、'1'、'%'。 - 单引号内只能包含一个字符,所以不能用单引号表示字符串。
- 双引号 (
""):- 双引号用于表示字符串字面量(String Literal)。
- 在双引号内可以包含多个字符,从零个字符到任意数量的字符。例如:
"Hello"、"Java is fun"、""(空字符串)。
示例:
char singleChar = 'A'; // 单字符字面量
String text = "Hello"; // 字符串字面量
String emptyString = ""; // 空字符串
总结:
- 单引号表示一个字符。
- 双引号表示一个字符串。
需要注意的是,Java中的字符是基本数据类型,而字符串是一个类(java.lang.String),所以字符字面量使用单引号,而字符串字面量使用双引号。
StringBuilder
StringBuilder 是 Java 中用于处理可变字符串的类,它可以在字符串末尾进行追加、插入、删除等操作,而不像 String 类型的对象一旦创建就不能改变。
以下是 StringBuilder 的一些常见用法示例:
创建一个新的 StringBuilder 对象:
StringBuilder sb = new StringBuilder();
在末尾追加字符串:
sb.append("Hello");
sb.append(" ");
sb.append("World");
插入字符串到指定位置:
sb.insert(5, " Awesome"); // 在索引 5 处插入 " Awesome"
删除字符串的一部分:
sb.delete(0, 6); // 删除索引从 0 到 5 的部分
更新特定位置的字符:
sb.setCharAt(0, 'J'); // 将索引 0 处的字符替换为 'J'
获取字符串长度:
int length = sb.length();
将 StringBuilder 转换为字符串:
String result = sb.toString();
由于 StringBuilder 是可变的,它可以减少字符串拼接和修改操作时的性能开销,特别是在需要多次修改字符串内容的情况下。在大量字符串拼接的场景中,使用 StringBuilder 通常比直接使用 String 效率更高。
以下是一个示例,展示了如何使用 StringBuilder 来构建一个句子:
StringBuilder sb = new StringBuilder();
sb.append("The")
.append(" quick")
.append(" brown")
.append(" fox")
.insert(10, " jumps")
.delete(15, 20)
.append(" over")
.append(" the")
.append(" lazy")
.append(" dog.");
String sentence = sb.toString();
System.out.println(sentence); // 输出: "The quick brown jumps over the lazy dog."
需要注意的是,虽然 StringBuilder 是线程不安全的(不同线程同时修改同一个 StringBuilder 实例可能导致问题),如果在多线程环境下使用,可以考虑使用线程安全的 StringBuffer 类。
StringBuilder 在处理字符串拼接和修改时具有许多优势,主要体现在性能和可用性方面:
- 可变性:
StringBuilder允许在已有字符串的基础上进行修改、拼接、插入、删除等操作,而不需要每次都创建新的字符串对象。这可以大大减少内存的使用和垃圾回收的开销,特别是在需要频繁修改字符串内容的情况下。 - 性能: 由于字符串是不可变的,每次对字符串进行修改或拼接都会产生一个新的字符串对象,原始字符串对象也不会立即被回收。这可能导致在频繁修改字符串时产生大量临时对象,影响性能。
StringBuilder避免了这种问题,它在内部使用可变的字符数组来存储字符串内容,从而避免了不必要的对象创建和销毁,提高了性能。 - 线程不安全性: 虽然
StringBuilder在单线程环境下表现良好,但它是非线程安全的。这意味着如果多个线程同时访问和修改同一个StringBuilder实例,可能会导致竞态条件和不一致性。然而,这也有一个好处:由于它不需要进行额外的线程同步操作,所以在单线程环境下的性能较高。 - 方法链式调用:
StringBuilder的方法通常可以链式调用,这样可以更加流畅地进行多个操作,提高代码的可读性。
综上所述,StringBuilder 是在需要频繁进行字符串操作时的一个很好的选择。然而,如果你在多线程环境下操作字符串,你可能需要考虑使用线程安全的 StringBuffer 或者采用适当的同步措施。
Collections类/Collections Class
sort(List<T> list):
List<Integer> numbers = new ArrayList<>(Arrays.asList(3, 1, 2, 4));
Collections.sort(numbers);
sort(List<T> list, Comparator<? super T> c):
List<String> names = new ArrayList<>(Arrays.asList("Alice", "Bob", "Eve"));
Collections.sort(names, (a, b) -> a.compareTo(b));
reverse(List<?> list):
List<String> names = new ArrayList<>(Arrays.asList("Alice", "Bob", "Eve"));
Collections.reverse(names);
shuffle(List<?> list)随机打乱列表中元素的顺序:
List<Integer> numbers = new ArrayList<>(Arrays.asList(1, 2, 3, 4));
Collections.shuffle(numbers);
binarySearch(List<? extends Comparable<? super T>> list, T key):
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
int index = Collections.binarySearch(numbers, 3);
binarySearch(List<? extends T> list, T key, Comparator<? super T> c):
List<String> names = Arrays.asList("Alice", "Bob", "Eve", "Zoe");
int index = Collections.binarySearch(names, "Bob", (a, b) -> a.compareTo(b));
max(Collection<? extends T> coll):
List<Integer> numbers = Arrays.asList(1, 3, 5, 2, 4);
Integer max = Collections.max(numbers);
max(Collection<? extends T> coll, Comparator<? super T> comp):
List<String> names = Arrays.asList("Alice", "Bob", "Eve", "Zoe");
String max = Collections.max(names, (a, b) -> a.compareTo(b));
min(Collection<? extends T> coll):
List<Integer> numbers = Arrays.asList(1, 3, 5, 2, 4);
Integer min = Collections.min(numbers);
min(Collection<? extends T> coll, Comparator<? super T> comp):
List<String> names = Arrays.asList("Alice", "Bob", "Eve", "Zoe");
String min = Collections.min(names, (a, b) -> a.compareTo(b));
replaceAll(List<T> list, T oldVal, T newVal)将列表中所有的旧值替换为新值:
List<Integer> numbers = new ArrayList<>(Arrays.asList(1, 2, 2, 3, 4, 2));
Collections.replaceAll(numbers, 2, 5);
frequency(Collection<?> c, Object o)计算集合中某个元素出现的次数:
List<String> names = Arrays.asList("Alice", "Bob", "Eve", "Bob", "Alice");
int frequency = Collections.frequency(names, "Bob");
unmodifiableCollection(Collection<? extends T> c)返回一个不可修改的集合:
List<Integer> numbers = Arrays.asList(1, 2, 3, 4, 5);
Collection<Integer> unmodifiable = Collections.unmodifiableCollection(numbers);
synchronizedCollection(Collection<T> c)返回一个同步(线程安全)的几核,支持多线程操作:
List<Integer> numbers = new ArrayList<>();
Collection<Integer> synchronizedCollection = Collections.synchronizedCollection(numbers);
singletonList(T o)返回包含一个指定元素的不可修改列表:
List<String> singleList = Collections.singletonList("Singleton");
singletonMap(K key, V value)返回包含一个指定键值对的不可修改映射:
Map<String, Integer> singletonMap = Collections.singletonMap("key", 42);
emptyList()返回一个空的不可修改列表:
List<String> emptyList = Collections.emptyList();
emptySet()返回一个空的不可修改集合:
Set<Integer> emptySet = Collections.emptySet();
emptyMap()返回一个空的不可修改映射:
Map<String, Integer> emptyMap = Collections.emptyMap();
addAll(Collection<? super T> c, T... elements)将指定的元素添加到集合中:
List<Integer> numbers = new ArrayList<>();
Collections.addAll(numbers, 1, 2, 3, 4, 5);
List接口/List Interface
在 Java 中,List 是一个接口,它继承自 Collection 接口,用于表示一个有序的元素集合。List 接口的实现类包括 ArrayList、LinkedList、Vector 等。下面是一些常见的 List 接口的方法:
创建一个 ArrayList:
import java.util.List;
import java.util.ArrayList;
public class Main {
public static void main(String[] args) {
// 创建一个 ArrayList
List<Integer> list = new ArrayList<>();
}
}
插入元素:
list.add(5); // [5]
list.add(10); // [5, 10]
list.add(7); // [5, 10, 7]
获取元素:
int firstElement = list.get(0); // 返回 5
删除元素:
list.remove(1); // 删除索引为 1 的元素,列表变为 [5, 7]
判断是否包含元素:
boolean containsFive = list.contains(5); // 返回 true
获取列表大小:
int size = list.size(); // 返回 2
清空列表:
list.clear(); // 列表变为空
添加多个元素:
List<String> stringList = new ArrayList<>();
stringList.addAll(List.of("apple", "banana", "cherry")); // ["apple", "banana", "cherry"]
获取子列表:
List<String> subList = stringList.subList(1, 3); // 得到包括索引1但不包括索引3的子列表,["banana", "cherry"]
修改元素:
list.set(1, 15); // 将索引为 1 的元素改为 15
转换为数组:
Integer[] array = list.toArray();
判断列表是否为空:
list.isEmpty();
迭代和遍历 - 使用增强的 for 循环:
for (Integer value : list) {
System.out.println(value);
}
迭代和遍历 - 使用迭代器:
Iterator<Integer> iterator = list.iterator();
while (iterator.hasNext()) {
Integer value = iterator.next();
System.out.println(value);
}
LinkedList类/LinkedList Class
LinkedList 是 Java 中的一个常见类,用于实现双向链表数据结构。当使用 LinkedList 时,以下是一些常见操作的代码示例:
创建和初始化 LinkedList:
LinkedList<String> linkedList = new LinkedList<>();
linkedList.add("Apple");
linkedList.add("Banana");
linkedList.add("Cherry");
添加元素:
在链表的开头添加元素:
linkedList.addFirst("Grapes");在链表的末尾添加元素:
linkedList.addLast("Dragonfruit");在指定位置插入元素:
linkedList.add(2, "Orange");
获取元素:
获取第一个元素:
String firstElement = linkedList.getFirst();获取最后一个元素:
String lastElement = linkedList.getLast();获取指定位置的元素:
String elementAtIndex = linkedList.get(3);
删除元素:
删除并返回第一个元素:
String removedElement = linkedList.removeFirst();删除并返回最后一个元素:
String removedElement = linkedList.removeLast();删除指定位置的元素:
String removedElement = linkedList.remove(2);
判断元素是否存在:
检查链表是否包含元素 “Banana”:
boolean containsBanana = linkedList.contains("Banana");
获取链表大小:
获取链表中的元素个数:
int size = linkedList.size();
判断链表是否为空:
检查链表是否为空:
boolean isEmpty = linkedList.isEmpty();
迭代遍历链表:
使用迭代器遍历链表:
Iterator<String> iterator = linkedList.iterator(); while (iterator.hasNext()) { String element = iterator.next(); // 处理元素 }使用增强的 for-each 循环遍历链表:
for (String element : linkedList) { // 处理元素 }
清空链表:
清空链表中的所有元素:
linkedList.clear();
Map接口/Map Interface
Map 是 Java 中的一个接口,它定义了一种将键映射到值的数据结构,具体的实现包括 HashMap、TreeMap、LinkedHashMap 等。下面是 Map 接口的常见操作:
插入元素(Put): 使用 put(key, value) 方法将一个键值对添加到 Map 中。
Map<String, Integer> map = new HashMap<>();
map.put("apple", 5);
map.put("banana", 3);
获取值(Get): 使用 get(key) 方法根据键获取对应的值。
Integer appleCount = map.get("apple"); // 返回 5
获取值或默认值(Get Or Default Value): 使用 getOrDefault(key, defaultValue) 方法获取指定 key 对应对 value,如果找不到 key ,则返回设置的默认值。
Integer appleCount = map.getOrDefault("apple", 0); // 返回5,否则返回0
删除键值对(Remove): 使用 remove(key) 方法根据键删除对应的键值对。
map.remove("banana"); // 删除键为 "banana" 的键值对
判断是否包含键(Contains Key): 使用 containsKey(key) 方法检查是否包含指定的键。
boolean containsApple = map.containsKey("apple"); // 返回 true
判断是否包含值(Contains Value): 使用 containsValue(value) 方法检查是否包含指定的值。
boolean hasFive = map.containsValue(5); // 返回 true
获取键集合(Key Set): 使用 keySet() 方法获取存储在 Map 中的所有键的集合。
Set<String> keys = map.keySet();
获取值集合(Values): 使用 values() 方法获取存储在 Map 中的所有值的集合。
Collection<Integer> values = map.values();
获取键值对集合(Entry Set): 使用 entrySet() 方法获取存储在 Map 中的所有键值对的集合。
Set<Map.Entry<String, Integer>> entries = map.entrySet();
获取大小(Size): 使用 size() 方法获取 Map 中键值对的数量。
int size = map.size();
清空 Map(Clear): 使用 clear() 方法清空 Map 中的所有键值对。
map.clear();
Set接口/Set Interface
添加元素:
Set<String> set = new HashSet<>();
boolean addResult = set.add("Apple");
这段代码创建了一个 HashSet 实例,然后使用 add 方法将字符串 “Apple” 添加到集合中。add 方法返回一个布尔值,表示添加是否成功。
移除元素:
boolean removeResult = set.remove("Apple");
使用 remove 方法从集合中移除指定的元素 “Apple”。remove 方法返回一个布尔值,表示移除是否成功。
清空集合:
set.clear();
clear 方法将集合中的所有元素移除,使集合为空。
查询元素:
set.add("Banana");
boolean containsResult = set.contains("Banana");
使用 contains 方法检查集合中是否包含元素 “Banana”。contains 方法返回一个布尔值,表示集合中是否包含指定元素。
获取集合大小:
int size = set.size();
使用 size 方法返回集合中元素的数量。
迭代集合:
set.add("Orange");
Iterator<String> iterator = set.iterator();
while (iterator.hasNext()) {
String element = iterator.next();
// 这里可以对元素 element 进行操作
}
使用迭代器遍历集合中的元素。iterator 方法返回一个迭代器对象,通过 hasNext 方法判断是否还有下一个元素,通过 next 方法获取下一个元素。
转换为数组:
Object[] array = set.toArray();
使用 toArray 方法将集合转换为数组。返回的数组类型是 Object[]。
转换为指定类型的数组:
String[] stringArray = set.toArray(new String[0]);
使用 toArray 方法将集合转换为指定类型的数组,这里是 String[]。传递一个合适长度的数组作为参数,返回的数组类型与参数类型相同。
或者使用Java8的Stream将集合转换为数组。这个想法是将给定的集合转换为流使用 Set.stream() 方法和用途 Stream.toArray() 方法返回一个包含流元素的数组。有两种方法可以做到这一点:
通过方法参考使用 Streams
Set<Integer> set = new HashSet<>(Arrays.asList(1, 2, 3, 4, 5));
Integer[] array = set.stream().toArray(Integer[]::new);
System.out.println(Arrays.toString(array));
使用带有 lambda 表达式的 Streams
Set<Integer> set = new HashSet<>(Arrays.asList(1, 2, 3, 4, 5));
Integer[] array = set.stream().toArray(n -> new Integer[n]);
System.out.println(Arrays.toString(array));
代码随想录中常用
resSet.stream().mapToInt(x -> x).toArray();
Deque接口/Deque Interface
Deque(双端队列)是Java集合框架中的接口,代表了一个可以在两端进行插入和删除操作的队列。Deque继承自Queue接口,提供了更丰富的操作,允许你在队列的头部和尾部进行添加、删除和检索元素。以下是一些Deque接口中常用的方法:
创建ArrayDeque/LinkedList对象:
在实现普通队列时,如何选择用 LinkedList 还是 ArrayDeque 呢?
总结来说就是推荐使用 ArrayDeque,因为效率高,而 LinkedList 还会有其他的额外开销(overhead)。
那 ArrayDeque 和 LinkedList 的区别有哪些呢?
- ArrayDeque 是一个可扩容的数组,LinkedList 是链表结构;
- ArrayDeque 里不可以存 null 值,但是 LinkedList 可以;
- ArrayDeque 在操作头尾端的增删操作时更高效,但是 LinkedList 只有在当要移除中间某个元素且已经找到了这个元素后的移除才是 O(1) 的;
- ArrayDeque 在内存使用方面更高效。
所以,只要不是必须要存 null 值,就选择 ArrayDeque 吧!
Deque<Integer> deque = new ArrayDeque<>();
Deque<Integer> deque = new LinkedList<>();
添加元素:
addFirst(element):将元素添加到队列的头部。addLast(element):将元素添加到队列的尾部。offerFirst(element):类似于addFirst,但是如果无法添加元素(如容量限制),会返回false。offerLast(element):类似于addLast,但是如果无法添加元素,会返回false。
deque.addFirst(1);
deque.addLast(2);
deque.offerFirst(0);
deque.offerLast(3);
deque.push(1); // stack的push操作也可以直接实现
deque.offer(1); // queue的offer操作也可以直接实现
获取并删除元素:
removeFirst():移除并返回队列头部的元素,如果队列为空会抛出异常。removeLast():移除并返回队列尾部的元素,如果队列为空会抛出异常。pollFirst():类似于removeFirst,但如果队列为空,会返回null。pollLast():类似于removeLast,但如果队列为空,会返回null。
int removedFirst = deque.removeFirst();
int removedLast = deque.removeLast();
int pollFirst = deque.pollFirst();
int pollLast = deque.pollLast();
deque.pop(); // stack的pop操作也可以直接实现
deque.poll(); // queue的poll操作也可以直接实现
获取但不删除元素:
getFirst():获取队列头部的元素,如果队列为空会抛出异常。getLast():获取队列尾部的元素,如果队列为空会抛出异常。peekFirst():类似于getFirst,但如果队列为空,会返回null。peekLast():类似于getLast,但如果队列为空,会返回null。
int firstElement = deque.getFirst();
int lastElement = deque.getLast();
int firstElement = deque.peekFirst();
int lastElement = deque.peekLast();
其他操作:
size():返回队列中的元素个数。isEmpty():检查队列是否为空。clear():清空队列中的所有元素。
int size = deque.size();
boolean isEmpty = deque.isEmpty();
Stack类/Stack Class
在Java中,Stack类是一个经典的数据结构,它实现了后进先出(Last-In-First-Out,LIFO)的堆栈操作。你可以使用Stack类来管理一组对象,类似于物理世界中的堆栈,比如浏览器的后退按钮或者函数调用的调用栈。
以下是使用Java中的Stack类的一些常见用法:
创建Stack对象: 你需要首先导入
java.util.Stack包,然后通过以下方式创建一个Stack对象:Stack<Integer> stack = new Stack<>();压入元素(Push): 使用
push方法将元素压入栈中:stack.push(5); stack.push(10); stack.push(15);弹出元素(Pop): 使用
pop方法弹出并移除栈顶元素:int topElement = stack.pop(); // 弹出并返回栈顶元素获取栈顶元素(Peek): 使用
peek方法获取栈顶元素,但不会将其从栈中移除:int topElement = stack.peek(); // 获取栈顶元素但不移除判断栈是否为空: 使用
isEmpty方法来检查栈是否为空:boolean isEmpty = stack.isEmpty(); // 返回true如果栈为空获取栈的大小: 使用
size方法获取栈中元素的数量:int stackSize = stack.size(); // 返回栈中元素的数量遍历栈: 你可以使用迭代器或者增强型for循环来遍历栈中的元素:
for (Integer element : stack) { System.out.println(element); }注意事项:
- 在使用
pop或peek方法之前,最好先使用isEmpty方法检查栈是否为空,以避免空栈异常。 - Java中的
Stack类是线程安全的,但在并发环境下推荐使用Deque的实现类,如LinkedList,以获得更好的性能。
- 在使用
JDK 文档中对Vector的描述是这样的:Vector 类实现了一个可增长的对象数组。像数组一样,可以通过整型索引来获取内容,但是 Vector 的大小可以按照实际元素数量的需求进行增长或收缩。Vector 和 ArrayList 非常接近,区别在于 ArrayList 的实现是非同步的,在多线程环境中可能出现线程不安全的情况,而 Vector 则是线程安全的。
Stack 类实现的就是我们非常常用的一种数据结构,栈,也称之为后进先出队列(LIFO)。栈的基本概念自不必多说,Java 中 Stack 类是基于 Vector 来实现的。
实际上,Vector 和 Stack 类已经不被推荐使用了,之所以仍然还保留是出于兼容性方面的考虑。通常情况下可以使用 ArrayList 来替代 Vector,在一些需要保证线程安全的情况下在外部进行同步或者使用Collections.synchronizedList方法。至于 Stack,官方的推荐是使用 Deque 接口的实现进行替代。
Queue接口/Queue Interface
在Java中,Queue接口代表了一个队列数据结构,它按照先进先出(First-In-First-Out,FIFO)的顺序管理元素。Queue接口有许多实现类,每个实现类都提供了不同的特性,让你可以根据需要选择适合的实现。
以下是使用Java中的Queue接口及其常见实现类的一些常见用法:
创建Queue对象: 首先,你需要导入
java.util.Queue包。然后可以通过多种方式创建Queue对象。常用的实现类包括:LinkedList: 可以用作Queue的实现,同时也是Deque的实现。ArrayDeque: 也是Deque的实现,支持双端队列操作。PriorityQueue: 基于优先级的队列,元素按照指定的排序规则进行排列。
例如,使用
LinkedList实现的队列:Queue<Integer> queue = new LinkedList<>();添加元素(Enqueue): 使用
add、offer方法将元素添加到队列的末尾:queue.add(5); queue.offer(10); queue.add(15);移除并获取队头元素(Dequeue): 使用
remove、poll方法移除并获取队头元素:int frontElement = queue.remove(); // 移除并返回队头元素 int frontElement = queue.poll(); // 移除并返回队头元素,如果队列为空则返回null获取队头元素(Peek): 使用
element、peek方法获取队头元素,但不会将其从队列中移除:int frontElement = queue.element(); // 获取队头元素但不移除 int frontElement = queue.peek(); // 获取队头元素但不移除,如果队列为空则返回null判断队列是否为空: 使用
isEmpty方法来检查队列是否为空:boolean isEmpty = queue.isEmpty(); // 返回true如果队列为空获取队列大小: 使用
size方法获取队列中元素的数量:int queueSize = queue.size(); // 返回队列中元素的数量遍历队列: 可以使用迭代器或者增强型for循环来遍历队列中的元素:
for (Integer element : queue) { System.out.println(element); }注意事项:
- 在使用
remove、poll、element、peek方法之前,最好先使用isEmpty方法检查队列是否为空,以避免异常。 PriorityQueue实现类允许你在队列中存储可排序的元素,元素会按照自然顺序或自定义比较器的规则进行排序。
- 在使用
总之,Java中的Queue接口及其实现类提供了一种方便的方式来管理队列数据结构,可以用于各种场景,如任务调度、消息传递等。你可以根据需求选择合适的实现类。
PriorityQueue类/PriorityQueue Class
PriorityQueue是Java中的一个优先级队列实现类,它是基于优先级堆的数据结构。在优先级队列中,元素按照优先级进行排序,具有最高优先级的元素会在队列操作时被最先处理。
以下是使用PriorityQueue的常见用法:
创建PriorityQueue对象: 首先,你需要导入
java.util.PriorityQueue包,然后可以通过以下方式创建一个PriorityQueue对象:PriorityQueue<Integer> priorityQueue = new PriorityQueue<>();添加元素: 使用
add、offer方法将元素添加到优先级队列中。元素会根据自然顺序或自定义比较器的规则进行排序:priorityQueue.add(5); priorityQueue.offer(10); priorityQueue.add(3);获取并移除队头元素: 使用
poll方法获取并移除队头元素(具有最高优先级的元素):int highestPriorityElement = priorityQueue.poll();获取队头元素: 使用
peek方法获取队头元素(具有最高优先级的元素),但不会将其从队列中移除:int highestPriorityElement = priorityQueue.peek();自定义优先级规则: 默认情况下,
PriorityQueue使用元素的自然顺序来进行排序。如果要使用自定义的比较器来定义优先级规则,你可以在创建队列时传入比较器对象:PriorityQueue<Integer> customPriorityQueue = new PriorityQueue<>((a, b) -> b - a); // 使用逆序比较器遍历队列:
PriorityQueue没有提供直接的迭代方法,但你可以将队列转换为数组或者列表,然后进行遍历:List<Integer> priorityList = new ArrayList<>(priorityQueue); for (Integer element : priorityList) { System.out.println(element); }注意事项:
- 当在队列中添加自定义对象时,确保对象的类实现了
Comparable接口或者在创建队列时提供了合适的比较器。 PriorityQueue并不是线程安全的,如果在多线程环境中使用,需要进行适当的同步操作。
- 当在队列中添加自定义对象时,确保对象的类实现了
PriorityQueue在许多情况下都很有用,比如任务调度、负载均衡、Dijkstra算法等需要处理优先级的场景。通过灵活地使用自然排序和自定义比较器,你可以有效地管理元素的优先级。
Math类/Math Class
- 绝对值和符号:
Math.abs(x):返回 x 的绝对值。Math.signum(x):返回 x 的符号,如果 x 为负则返回 -1.0,如果 x 为正则返回 1.0,如果 x 为零则返回 0.0。
- 取整和取余:
Math.ceil(x):返回不小于 x 的最小整数。Math.floor(x):返回不大于 x 的最大整数。Math.round(x):返回最接近 x 的整数,四舍五入。Math.max(x, y):返回 x 和 y 中较大的值。Math.min(x, y):返回 x 和 y 中较小的值。
- 幂运算和开方:
Math.pow(x, y):返回 x 的 y 次幂。Math.sqrt(x):返回 x 的平方根。Math.cbrt(x):返回 x 的立方根。
- 三角函数:
Math.sin(x)、Math.cos(x)、Math.tan(x):分别返回 x 的正弦、余弦和正切值。Math.asin(x)、Math.acos(x)、Math.atan(x):分别返回 x 的反正弦、反余弦和反正切值。Math.atan2(y, x):返回 y/x 的反正切值,可以得到角度的弧度表示。
- 指数和对数:
Math.exp(x):返回 e 的 x 次幂。Math.log(x):返回 x 的自然对数。Math.log10(x):返回 x 的以 10 为底的对数。
- 随机数:
Math.random():返回一个 0 到 1 之间的随机 double 值。
- 其他常量:
Math.PI:圆周率 π 的近似值。Math.E:自然对数的底数 e 的近似值。
Arrays类/Arrays Class
java.util.Arrays 类提供了许多用于操作数组的常见方法。以下是一些常见的 Arrays 类方法及其用法:
排序数组:
int[] arr = {5, 2, 8, 1, 6};
Arrays.sort(arr); // 对数组进行升序排序
搜索元素:
int[] arr = {5, 2, 8, 1, 6};
int index = Arrays.binarySearch(arr, 8); // 在已排序数组中二分查找元素的索引,返回 2
填充数组:
int[] arr = new int[5];
Arrays.fill(arr, 0); // 将数组所有元素填充为 0
复制数组:
int[] source = {1, 2, 3};
int[] destination = Arrays.copyOf(source, source.length); // 复制数组到一个新的数组
比较数组:
int[] arr1 = {1, 2, 3};
int[] arr2 = {1, 2, 3};
boolean isEqual = Arrays.equals(arr1, arr2); // 比较两个数组是否相等,返回 true
数组转换为字符串:
int[] arr = {1, 2, 3};
String arrString = Arrays.toString(arr); // 将数组转换为字符串形式,返回 "[1, 2, 3]"
数组的填充范围:
int[] arr = new int[5];
Arrays.fill(arr, 1, 4, 8); // 将数组的索引 1 到 3(不包括索引 4)的元素填充为 8
数组元素的哈希码:
int[] arr = {1, 2, 3};
int hashCode = Arrays.hashCode(arr); // 返回数组元素的哈希码
将数组转化为list:
首先,该方法是将数组转化为list。有以下几点需要注意:
(1)该方法不适用于基本数据类型(byte,short,int,long,float,double,boolean)
(2)该方法将数组与列表链接起来,当更新其中之一时,另一个自动更新
(3)不支持add和remove方法
在java语言中,把数组转换成List集合,有个很方便的方法就是
List<String> list = Arrays.asList("a","b","c");
但你可能不知道这样得到的List它的长度是不能改变的。当你向这个List添加或删除一个元素时(例如 list.add(“d”);)程序就会抛出异常java.lang.UnsupportedOperationException。
怎么会这样?!只需要看看asList()方法是怎么实现的就行了。
@SafeVarargs
@SuppressWarnings("varargs")
public static <T> List<T> asList(T... a) {
return new ArrayList<>(a);
}
当你看到这段代码时可能觉得没啥问题啊,不就是返回了一个ArrayList对象吗?问题就出在这里。这个ArrayList不是java.util包下的,而是java.util.Arrays.ArrayList,显然它是Arrays类自己定义的一个内部类!这个内部类没有实现add()、remove()方法,而是直接使用它的父类AbstractList的相应方法。而AbstractList中的add()和remove()是直接抛出java.lang.UnsupportedOperationException异常的!
总结一下吧,如果你的List只是用来遍历,就用Arrays.asList()吧!如果你的List还要添加或删除元素,还是乖乖地new一个java.util.ArrayList,然后一个一个的添加元素吧!
String类/String Class
length():
String str = "Hello, world!";
int length = str.length();
System.out.println("Length of the string: " + length);
charAt(int index):
String str = "Java";
char ch = str.charAt(2); // Returns the character 'v' at index 2
System.out.println("Character at index 2: " + ch);
equals(Object another):
String str1 = "Hello";
String str2 = "Hello";
boolean isEqual = str1.equals(str2);
System.out.println("Strings are equal: " + isEqual);
substring(int beginIndex, int endIndex): 此方法返回从指定开始索引到结束索引之前的子字符串。
String str = "Hello, world!";
String substr = str.substring(7, 12); // Returns "world"
System.out.println("Substring: " + substr);
indexOf(String str):
String str = "Java programming";
int index = str.indexOf("programming"); // Returns the index 5
System.out.println("Index of 'programming': " + index);
startsWith(String prefix):
String str = "Hello, world!";
boolean startsWithHello = str.startsWith("Hello"); // Returns true
System.out.println("Starts with 'Hello': " + startsWithHello);
toUpperCase():
String str = "java";
String upperCaseStr = str.toUpperCase(); // Returns "JAVA"
System.out.println("Uppercase string: " + upperCaseStr);
replace(char oldChar, char newChar):
String str = "Hello, world!";
String replacedStr = str.replace('o', '0'); // Returns "Hell0, w0rld!"
System.out.println("Replaced string: " + replacedStr);
split(String regex):
String str = "apple,banana,grape";
String[] fruits = str.split(",");
for (String fruit : fruits) {
System.out.println("Fruit: " + fruit);
}
join(CharSequence delimiter, CharSequence… elements):
String[] words = {"Hello", "world", "Java"};
String joinedString = String.join(" ", words); // Returns "Hello world Java"
System.out.println("Joined string: " + joinedString);
Character类/Character Class
Character 类是 Java 中用来表示字符的包装类,它提供了一系列方法来操作字符。以下是一些常用的 Character 类的方法:
isLetter(char ch):检查字符是否是一个字母。
char ch = 'A';
boolean isLetter = Character.isLetter(ch); // 返回 true
isDigit(char ch):检查字符是否是一个数字。
char ch = '5';
boolean isDigit = Character.isDigit(ch); // 返回 true
isWhitespace(char ch):检查字符是否为空白字符,如空格、制表符或换行符。
char ch = ' ';
boolean isWhitespace = Character.isWhitespace(ch); // 返回 true
isUpperCase(char ch):检查字符是否是大写字母。
char ch = 'A';
boolean isUpperCase = Character.isUpperCase(ch); // 返回 true
isLowerCase(char ch):检查字符是否是小写字母。
char ch = 'a';
boolean isLowerCase = Character.isLowerCase(ch); // 返回 true
toUpperCase(char ch):将字符转换为大写字母。
char ch = 'a';
char upperCase = Character.toUpperCase(ch); // upperCase 等于 'A'
toLowerCase(char ch):将字符转换为小写字母。
char ch = 'A';
char lowerCase = Character.toLowerCase(ch); // lowerCase 等于 'a'
toString(char ch):将字符转换为字符串。
char ch = 'X';
String str = Character.toString(ch); // str 等于 "X"
这些方法使得在处理字符时更加方便,可以进行各种字符类型的检查和转换操作。请注意,Character 类的方法通常是静态方法,因此可以直接通过类名调用,而不需要创建 Character 对象。
Integer类/Integer Class
Integer是Java中的一个包装类,用于将基本数据类型int封装为对象。通过Integer类,你可以在需要对象的地方使用整数,并且还提供了许多有用的方法来操作和处理整数数据。以下是关于Integer类的一些重要信息:
将整数转换为Integer对象:
int primitiveInt = 42;
Integer integerObj = Integer.valueOf(primitiveInt);
将字符串转换为整数:
String numStr = "123";
int parsedInt = Integer.parseInt(numStr);
将Integer对象转换为基本数据类型int:
Integer integerObj = Integer.valueOf(42);
int intValue = integerObj.intValue();
比较两个Integer对象的值:
Integer firstInt = Integer.valueOf(10);
Integer secondInt = Integer.valueOf(20);
int comparison = firstInt.compareTo(secondInt);
if (comparison < 0) {
System.out.println("The first value is smaller.");
} else if (comparison > 0) {
System.out.println("The second value is smaller.");
} else {
System.out.println("Both values are equal.");
}
检查两个对象是否相等:
Integer num1 = Integer.valueOf(5);
int num2 = 5;
if (num1.equals(num2)) {
System.out.println("The values are equal.");
}
将整数转换为二进制字符串:
int intValue = 42;
String binaryStr = Integer.toBinaryString(intValue);
System.out.println("Binary representation: " + binaryStr);
这些示例展示了Integer类的一些常见用法,包括将整数转换为对象、进行数值转换、比较值、检查相等性以及获取二进制表示等操作。你可以根据实际需求在代码中应用这些用法。
常用位运算技巧
算法 - 超全的位运算介绍与总结 - bigsai - SegmentFault 思否
前言
位运算隐藏在编程语言的角落中,其神秘而又强大,暗藏内力,有些人光听位运算的大名的心中忐忑,还有些人更是一看到位运算就远远离去,我之前也是。但狡猾的面试官往往喜欢搞偷袭,抓住我们的弱点搞我们,为了防患于未然,特记此篇!
本篇的内容为位运算的介绍和一些比较经典的位运算问题进行介绍分析,当然,位运算这么牛,后面肯定还是要归纳总结的。
认识位运算
什么是位运算?
程序中的所有数在计算机内存中都是以二进制的形式储存的。位运算就是直接对整数在内存中的二进制位进行操作。
位运算就是直接操作二进制数,那么有哪些种类的位运算呢?
常见的运算符有与(&)、或(|)、异或(^)、取反(~)、左移(«)、右移(»是带符号右移 »>无符号右移动)。下面来细看看每一种位运算的规则。
位运算 & (与)
规则:二进制对应位两两进行逻辑AND运算(只有对应位的值都是 1 时结果才为 1, 否则即为 0)即 0&0=0, 0&1=0, 1&1=1
例如:2 & -2

位运算 | (或)
规则:二进制对应位两两进行逻辑或运算(对应位中有一 个为1则为1) 即0|0=0,0|1=1,1|1=1
例如:2 | -2

位运算 ^ (异或)
规则:二进制对应位两两进行逻辑XOR (异或) 的运算(当对应位的值不同时为 1, 否则为 0)即0^0=0, 0^1=1, 1^1=0
例如:2 ^ -2

按位取反~
规则:二进制的0变成1,1变成0。

移位运算符
左移运算<<:左移后右边位补 0
右移运算>>:右移后左边位补原最左位值(可能是0,可能是1)
右移运算>>>:右移后左边位补 0
- 对于左移运算符
<<没有悬念右侧填个零无论正负数相当于整个数乘以2。 - 而右移运算符就有分歧了,分别是左侧补0
>>>和左侧补原始位>>,如果是正数没争议左侧都是补0,达到除以2的效果;如果是负数的话左侧补0>>>那么数值的正负会发生改变,会从一个负数变成一个相对较大的正数。而如果是左侧补原始位(负数补1)>>那么整个数还是负数,也就是相当于除以2的效果。
下面这张图可以很好的帮助你理解负数的移位运算符:

到这里,我想你应该对位运算有了初步的认识,在这里把上面提到的部分案例执行对比一下让你看一下可能会理解的更清晰:

位运算小技巧
在这里有些常用的位运算小技巧。
判断奇偶数
正常判断奇数偶数的时候我们会这样写:
if( n % 2 == 1) // n 是个奇数 }
使用位运算可以这么写:
if(n & 1 == 1){ // n 是个奇数。 }
其核心就是判断二进制的最后一位是否为1,如果为1那么结果加上2^0=1一定是个奇数,否则就是个偶数。
交换两个数
对于传统的交换两个数,我们需要使用一个变量来辅助完成操作,可能会是这样:
int team = a; a = b; b = team;
但是使用位运算可以不需要借助额外空间完成数值交换:
a=a^b;//a=a^b b=a^b;//b=(a^b)^b=a^0=a a=a^b;//a=(a^b)^(a^b^b)=0^b=0
原理已经写在注释里面了,是不是感觉非常diao呢?
二进制枚举
在遇到子集问题的处理时候,我们有时候会借助二进制枚举来遍历各种状态(效率大于dfs回溯)。这种就属于排列组合的问题了,对于每个物品(位置)来说,就是使用和不使用的两个状态,而在二进制中刚好可以用1和0来表示。而在实现上,通过枚举数字范围分析每个二进制数字各符号位上的特征进行计算求解操作即可。

二进制枚举的代码实现为:
for(int i = 0; i < (1<<n); i++) //从0~2^n-1个状态
{
for(int j = 0; j < n; j++) //遍历二进制的每一位 共n位
{
if(i & (1 << j))//判断二进制数字i的第j位是否存在
{
//操作或者输出
}
}
}
位运算经典问题
有了上面的位运算基础,我们怎么用位运算处理实际问题呢?或者有哪些经典的问题可以用位运算来解决呢。
不用加减乘除做加法
题目描述
写一个函数,求两个整数之和,要求在函数体内不得使用+、-、*、/四则运算符号。
分析:
这道题咋一听可能没啥思路,简单研究一下位运算还是能独立推出来和理解的。
当然,解决这题前,需要了解上面的四种位运算。还要知道二进制的运算:0+0=0,0+1=1,1+1=0(进位)
对于加法的一个二进制运算。如果不进位那么就是非常容易的。这时候相同位都为0则为0,0和1则为1.满足这种运算的异或(不相同取1,相同取0)和或(有一个1则为1)都能满足.
但事实肯定有进位的运算啊!看到上面操作的不足之后,我们肯定还需要解决进位的问题对于进位的两数相加,这种核心思想为:

- 用两个数,一个正常m相加(不考虑进位的)。用异或a^b就是满足这种要求,先不考虑进位(如果没进位那么就是最终结果)。另一个专门考虑进位的n。两个1需要进位。所以我们用a&b与记录需要进位的。但是还有个问题,进位的要往上面进位,所以就变成这个需要进位的数左移一位。
- 然后就变成m+n重新迭代开始上面直到不需要进位的(即n=0时候)。

实现代码为:
public class Solution {
public int Add(int num1,int num2) {
/*
* 5+3 5^3(0110) 5&3(0001)
* 0101
* 0011
*/
int a=num1^num2;
int b=num1&num2;
b=b<<1;
if (b==0)
return a;
else {
return Add(a, b);
}
}
}
当然,这里也可以科普一下二进制求加法:average = (a&b) + (a^b)»1
二进制中1的个数
这是一道经典题,在剑指offer上也有对应题目,其具体题目要求输入一个整数,输出该数二进制表示中1的个数(其中负数用补码表示)。
对于这个问题,不用位运算将它转成二进制字符串直接枚举字符'1’的个数也可以直接求出来,但是这样做是没有灵魂的并且效率比较差。这里提供两种解决思路
法一: 大家知道每个类型的数据它的背后实际都是二进制操作。大家知道int的数据类型的范围是(-2^31,2^31 -1)。并且int有32位。但是并非32位全部用来表示数据。真正用来表示数据大小的也是31位。最高位用来表示正负。
首先要知道:
1«0=1 =00000000000000000000000000000001
1«1=2 =00000000000000000000000000000010
1«2=4 =00000000000000000000000000000100
1«3=8 =00000000000000000000000000001000
. . . . . .
1«30=2^30 =01000000000000000000000000000000
1«31=-2^31 =10000000000000000000000000000000
其次还要知道位运算&与。两个十进制与运算.每一位同1为1。所以我们用2的正数次幂与知道的数分别进行与运算操作。如果结果不为0,那么就说明这位为1.(前面31个都是大于0的最后一个与结果是负数但是如果该位为1那么结果肯定不为0)

具体代码实现为:
public int NumberOf1(int n) {
int va=0;
for(int i=0;i<32;i++)
{
if((n&(1<<i))!=0)
{
va++;
}
}
return va;
}
法二是运用n&(n-1)。n如果不为0,那么n-1就是二进制第一个为1的变为0,后面全为1.这样的n&(n-1)一次运算就相当于把最后一个1变成0.这样一直到运算的数为0停止计算次数就好了,如下图共进行三次运算那么n的二进制中就有三个1。
实现代码为:

public class Solution {
public int NumberOf1(int n) {
int count=0;
while (n!=0) {
n=n&(n-1);
count++;
}
return count;
}
}
只出现一次的(一个)数字①
问题描述:
给定一个非空整数数组,除了某个元素只出现一次以外,其余每个元素均出现两次。找出那个只出现了一次的元素。
说明:你的算法应该具有线性时间复杂度。 你可以不使用额外空间来实现吗?
分析:
这是一道简单的面试题,面试官常问怎么样用不太复杂的方法找出数组中仅出现一次的数字(其他均出现两次),暴力枚举或者使用其他的存储结构都不够优化,而这个问题最高效的答案就是使用位运算。首先你要注意两点:
- 0和任意数字进行异或操作结果为数字本身.
- 两个相同的数字进行异或的结果为0.
具体的操作就是用0开始和数组中每个数进行异或,得到的值和下个数进行异或,最终获得的值就是出现一次(奇数次)的值。

class Solution {
public int singleNumber(int[] nums) {
int value=0;
for(int i=0;i<nums.length;i++)
{
value^=nums[i];
}
return value;
}
}
只出现一次的(一个)数字②
问题描述:
给定一个非空整数数组,除了某个元素只出现一次以外,其余每个元素均出现了三次。找出那个只出现了一次的元素。
说明:你的算法应该具有线性时间复杂度。 你可以不使用额外空间来实现吗?
分析:
这题和上一题的思路略有不同,这题其他数字出现了3次,那么我们如果直接使用位运算异或操作的话无法直接找到结果,就需要巧妙的运用二进制的其他特性:判断整除求余操作。即判断所有数字二进制1的总个数和0的总个数一定有一个不是三的整数倍,如果0不是三的整数倍那么就说明结果的该位二进制数字为0,同理否则为1.

在具体的操作实现上,问题中给出数组中的数据在int范围之内,那么我们就可以在实现上可以对int的32个位每个位进行依次判断该位1的个数求余3后是否为1,如果为1说明结果该位二进制为1可以将结果加上去。最终得到的值即为答案。
具体代码为:
class Solution {
public int singleNumber(int[] nums) {
int value=0;
for(int i=0;i<32;i++)
{
int sum=0;
for(int num:nums)
{
if(((num>>i)&1)==1)
{
sum++;
}
}
if(sum%3==1)
value+=(1<<i);
}
return value;
}
}
只出现一次的(两个)数字③
题目描述
一个整型数组里除了两个数字之外,其他的数字都出现了两次。请写程序找出这两个只出现一次的数字。
思路:
上面的问题处理和理解起来可能比较容易,但是这个问题可能稍微复杂一点,但是这题可以通过特殊的手段转化为上面只出现一次的一个数字问题来解决,当然核心的位运算也是异或^。
具体思路就是想办法将数组逻辑上一分为二!先异或一遍到最后得到一个数,得到的肯定是a^b(假设两个数值分别为a和b)的值。在看异或^的属性:不同为1,相同为0. 也就是说最终这个结果的二进制为1的位置上a和b是不相同的。而我们可以找到这个第一个不同的位,然后将数组中的数分成两份,该位为0的进行异或求解得到其中一个结果a,该位为1的进行异或求解得到另一个结果b。
具体可以参考下图流程:

实现代码为:
public int[] singleNumbers(int[] nums) {
int value[]=new int[2];
if(nums.length==2)
return nums;
int val=0;//异或求的值
for(int i=0;i<nums.length;i++)
{
val^=nums[i];
}
int index=getFirst1(val);
int num1=0,num2=0;
for(int i=0;i<nums.length;i++)
{
if(((nums[i]>>index)&1)==0)//如果这个数第index为0 和num1异或
num1^=nums[i];
else//否则和 num2 异或
num2^=nums[i];
}
value[0]=num1;
value[1]=num2;
return value;
}
private int getFirst1(int val) {
int index=0;
while (((val&1)==0&&index<32))
{
val>>=1;// val=val/2
index++;
}
return index;
}
结语
当然,上面的问题可能有更好的解法,也有更多经典位运算问题将在后面归纳总结,希望本篇的位运算介绍能够让你有所收获,对位运算能有更深一点的认识。对于很多问题例如博弈问题等二进制位运算能够很巧妙的解决问题,日后也会分享相关内容,敬请期待!
计算机术语笔记
子数组/Subarray
A subarray is a contiguous non-empty sequence of elements within an array. 连续非空!
奇偶性/Parity
回文/Palindrome
A palindrome is a sequence that reads the same forward and backward
同字母异位词/Anagram
An Anagram is a word or phrase formed by rearranging the letters of a different word or phrase, typically using all the original letters exactly once.
双向图/bi-directional graph
Peizhen Zheng
Graduate Research Assistant
My research interests include all fields of computer graphics.